Detectar y prevenir alucinaciones no es magia: es arquitectura.
En nuestro camino por reducir las alucinaciones de los agentes de IA que construimos nos hemos dado cuenta que no existe un enfoque universal para reducirlas y si quisiéramos listarlas todas, no nos cabría en un post…
Pero si tienes un agente de IA conectado a tools en n8n o LangChain estás de suerte, hay una manera de verificar sus respuestas.
PD: Y no hagas como la madre de este gato, pide verificaciones.

Agente evaluador: la técnica implementada para detener alucinaciones en n8n
Si a tu agente orquestador conectado a diferentes tools le preguntas «¿cuantos trabajadores han asistido hoy a mi empresa?» y te devuelve «100». ¿Cómo sabes si es verídica esa respuesta o se la ha inventado?
La gran mayoría de las veces accionará la herramienta correspondiente para responder, pero habrá ciertos momentos (ya sea por influencia del historial de conversación, mal interpretaciones de las preguntas o porque ese día estaba más vago de lo normal), puede que alucine, y eso es un problema.
La idea principal
Cuando un agente orquestador conectado a tools devuelve una respuesta, el framework de LangChain utilizado en n8n siempre nos dirá si utilizó o no una tool para formular la respuesta. Gracias a esto podemos detectar y prevenir alucinaciones.
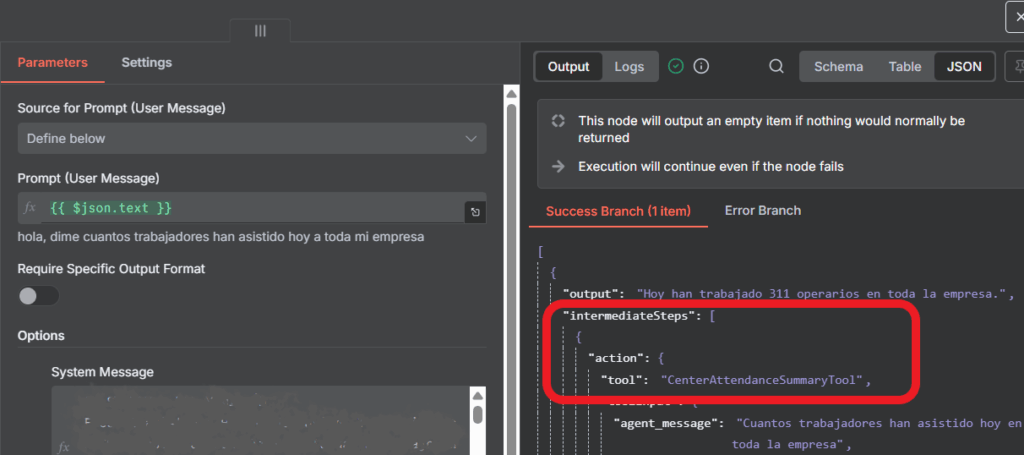
Si el orquestador ya usó tools (hay intermediateSteps), su respuesta se acepta y se envía directamente al usuario. Si no usó tools, pasamos la respuesta y el contexto por EvalAgent para decidir si debía usarlas o enviar la respuesta directamente al usuario.
Si EvalAgent determina NEED_TOOL, se reintenta con una instrucción precisa; si después de 3 evaluaciones seguimos igual, se corta el bucle.
El Evaluador inspecciona la respuesta del Orquestador, si no hay intermediateStep decide si debió usar tools y emite un JSON (verdict, required_tools, message_to_agent) conforme al schema definido.
Pros
– salidas auditables, validables y fáciles de testear.
Contras
– Más latencia y coste cuando hay que reintentar (evaluación + nueva ejecución).
– Hay que manejar dos prompts complejos (el del Orquestador y el del Evaluador).
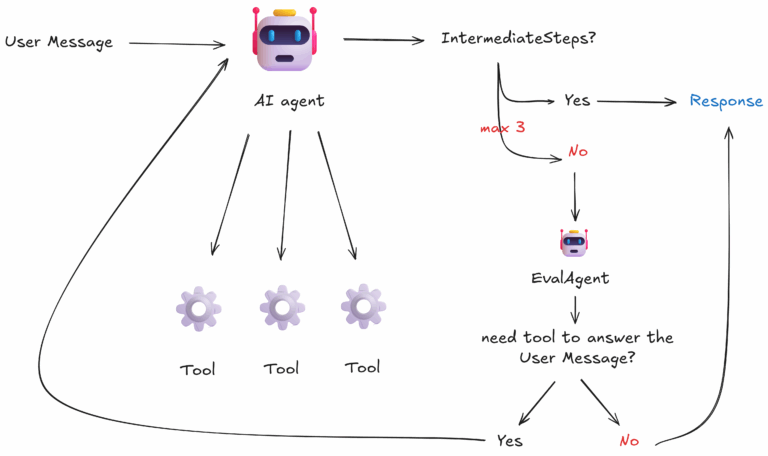
Componentes de la arquitectura
1) Usuario (envía solicitudes y preguntas)
2) Agente orquestador de n8n (LangChain) con acceso a tools.
3) Script de validación (determinístico): inspecciona si el output del orquestador incluye intermediateSteps.
4) Agente evaluador (EvalAgent): decide si hacía falta tools para contestar y, en su caso, qué tools y con qué instrucción.
5) Contador de iteraciones entre Orquestador ↔ Evaluador (máx. 3 evaluaciones por consulta) con el fin de prevenir bucles infinitos.
6) Finalizador: entrega la respuesta al usuario.
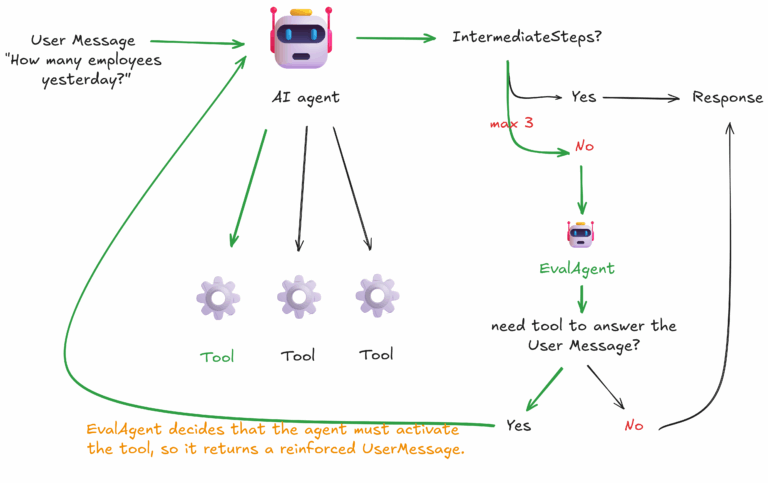
Ejemplo de flujo
– Entrada: llega el user_query del usuario «Hola».
– Orquestador ejecuta con su prompt y tiene acceso a todas las tools.
– Script de validación:
- Si el output incluye intermediateSteps (por ejemplo. llamadas a Tool, etc.) → acepta la respuesta.
- Si no, construye payload para EvalAgent: { context, user_query, agent_answer }.
– EvalAgent clasifica la intención y decide:
- verdict=»OK» → se acepta la respuesta sin tools.
- verdict=»NEED_TOOL» → devuelve required_tools + message_to_agent.
– Reintento:
El Orquestador se re-ejecuta con la instrucción de message_to_agent (y su política de tools).
Incrementa contador de iteraciones Orquestador↔Evaluador.
– Límite:
Si el contador llega a 3 evaluaciones y aún no hay intermediateSteps, detener y aplicar fallback de negocio (p. ej., “Lo siento, no puedo completar la consulta con datos verificados ahora.”).
– Salida:
Respuesta final al usuario (el Orquestador compone la salida solo con datos de las tools, según sus reglas).
Lecciones aprendidas:
– La mayoría de respuestas inventadas dadas por el agente sin accionar la tool correspondiente se han dado cuando le hemos pasado más de 4 interacciones como ventana de contexto de memoria. Si dejamos sin memoria contextual al agente orquestador, no devuelve respuestas inventadas (este descubrimiento y sus por qués dan para otro post..)
– Usar intermediateSteps como “prueba de trabajo” es muy útil para filtrar respuestas sin datos verificables. No podemos detectar alucinaciones venidas directamente del propio conocimiento del LLM, por ejemplo «quién fue el último presidente de Alemania» pero si las respuestas vienen de tools, podemos verificar que por lo menos, la tool fue utilizada para responder (ya integraremos en la tool las verificaciones determinísticas que haga falta). https://langchain-cn.readthedocs.io/en/latest/modules/agents/agent_executors/examples/intermediate_steps.html?utm_source=chatgpt.com
– Auditar y testear las respuestas de los agentes es clave para mejorar y JSON Schema ayuda mucho a ello. JSON Schema como contrato único endurece las validaciones y simplifica bastante los tests automatizados que queramos realizar. https://json-schema.org/draft/2020-12?utm_source=chatgpt.com
– Un buen prompt vale oro. Hasta conseguir el resultado deseado hemos iterado muchas veces, si digo 30 me quedo corto…

What's next?
If you have a similar idea you'd like to implement in your company, feel free to reach out. You can contact me at pablo@ideasforge.io