Automatizando la gestión de facturas con OCR + IA
La gestión de gastos operativos, como las facturas de servicios básicos (agua, luz, gas), representa a menudo una tarea ardua y costosa. Empresas que manejan múltiples proyectos o propiedades reciben continuamente miles de facturas, cuya información debe ser extraída, procesada y registrada en sistemas internos.
Tradicionalmente, este proceso se realiza de forma manual, constituyendo un cuello de botella operativo que consume tiempo y recursos valiosos.
Más allá del simple coste y la ineficiencia, la transcripción manual de datos desde documentos, especialmente cuando se trata de facturas escaneadas, introduce un riesgo significativo: el error humano. La fatiga visual, la monotonía de la tarea y la variabilidad en el formato y la calidad de los documentos aumentan la probabilidad de errores de transcripción, lo que puede llevar a discrepancias en la contabilidad, pagos incorrectos y problemas en la auditoría.
El desafío
En nuestro caso particular, la situación se agrava al tratar con facturas predominantemente escaneadas. A diferencia de los documentos digitales nativos, los documentos escaneados presentan desafíos adicionales para las tecnologías de Reconocimiento Óptico de Caracteres (OCR):
- Calidad de imagen variable: Resolución baja, compresión, ruido, manchas, arrugas.
- Distorsiones: Inclinación (skew), perspectiva, bordes cortados.
- Problemas de contraste e iluminación: Textos poco legibles.
- Variabilidad de formatos y fuentes: Diferentes proveedores utilizan diseños y tipografías muy diversos.
- Artefactos: Sellos, marcas de agua o anotaciones manuales que interfieren con el texto.
Esta complejidad inherente a los documentos escaneados dificulta considerablemente la extracción precisa de datos mediante métodos automatizados.
Investigación y selección del modelo OCR base
Comprendiendo la magnitud del problema y los desafíos técnicos, abordamos una investigación exhaustiva del estado del arte en modelos de OCR y procesamiento de documentos basados en inteligencia artificial. Nuestro objetivo era identificar la tecnología más robusta y precisa disponible en el mercado que pudiera manejar la complejidad de las facturas escaneadas.
Evaluamos varios modelos de lenguaje y visión líderes, incluyendo:
- Sonnet 3.5 de Claude (Anthropic)
- Gemini 1.5 Pro de Google AI
- Gemini 2.0 Flash de Google AI
- Mistral (diferentes variantes)
Realizamos pruebas rigurosas con un conjunto representativo de facturas escaneadas de distintos proveedores. Durante estas pruebas, identificamos rápidamente que algunos modelos, como ciertas variantes de Mistral, presentaban una tasa de error inaceptablemente alta para nuestro caso de uso, confundiendo dígitos similares (como el ‘5’ y el ‘9’) o letras (‘R’ y ‘F’), lo que invalidaba su utilidad para la extracción de datos financieros sensibles.
Tras comparar el rendimiento y la precisión en la extracción de información clave (nombres de proveedor, números de cuenta, fechas, importes, direcciones) de documentos escaneados complejos, Gemini 1.5 Pro y Sonnet 3.5 destacaron como las opciones más prometedoras. Ambos demostraron una notable capacidad para comprender el contexto de los documentos y extraer información con alta fiabilidad incluso en condiciones subóptimas.
¿Por qué Gemini 1.5 Pro para analizar las facturas?
La decisión final de decantarnos por Gemini 1.5 Pro se basó en una combinación óptima de rendimiento y consideraciones económicas. Si bien Sonnet 3.5 ofrecía un rendimiento comparable, su estructura de precios por token resultaba significativamente más elevada para el volumen de procesamiento requerido en este proyecto, en comparación con la rentabilidad y la eficiencia de Gemini 1.5 Pro, especialmente considerando su amplia ventana de contexto que permite procesar documentos largos de una sola vez. (Nota: Los precios por token varían y deben consultarse en la documentación actual del proveedor, pero históricamente Gemini 1.5 Pro ha sido más competitivo en coste para tareas de procesamiento de volumen con grandes contextos).
La solución: Arquitectura y flujo de trabajo
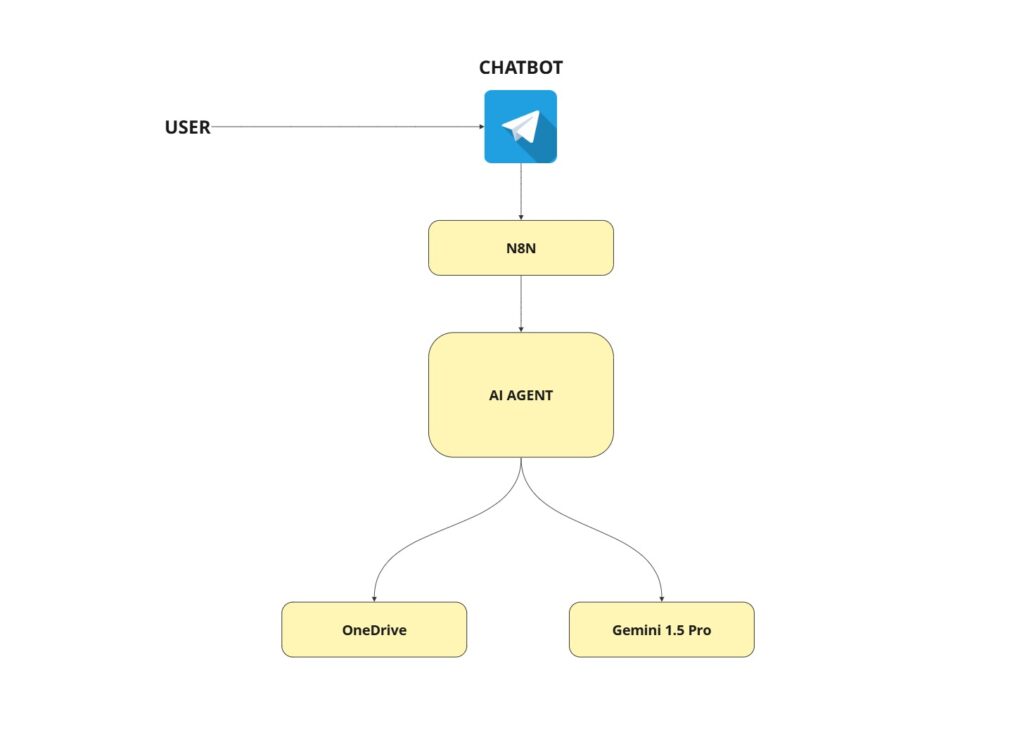
Para resolver el problema de la empresa constructora, diseñamos e implementamos una solución automatizada robusta utilizando una combinación de Python para tareas de procesamiento de bajo nivel y n8n como orquestador de flujos de trabajo (workflow automation tool). El proceso se estructura de la siguiente manera:
1. Ingesta y almacenamiento de documentos:
- Punto de entrada: Las facturas en formato PDF se envían inicialmente a través de un bot de Telegram, proporcionando una interfaz simple y accesible para los usuarios de la empresa.
- Almacenamiento centralizado: El bot de Telegram gestiona la subida automática de estos PDFs a una estructura de carpetas organizada en OneDrive. Esto no solo sirve como entrada para el procesamiento automatizado, sino que también crea un directorio digitalizado y estructurado de todas las facturas recibidas, facilitando futuras búsquedas y auditorías.
2. Pre-procesamiento con Python:
- Un script de Python monitorea la carpeta de entrada en OneDrive.
- Este script se encarga de procesar los PDFs, identificando documentos individuales (en caso de que un solo archivo contenga múltiples facturas) y asignando a cada factura un identificador único. Esto es crucial para el seguimiento a lo largo del flujo de trabajo.
3. Preparación para el modelo multimodal (Base64):
- Para aprovechar la capacidad multimodal de Gemini 1.5 Pro (que puede procesar texto e imágenes simultáneamente), es necesario enviar los datos de la imagen junto con la petición a su API.
- Aunque la API de Gemini 1.5 Pro permite el envío multimodal a través de peticiones HTTP, las imágenes de los PDFs deben estar en un formato adecuado para ser incluidas en el payload de la petición. El formato Base64 es un estándar común para codificar datos binarios (como imágenes) en una cadena de texto ASCII, lo que facilita su transmisión a través de protocolos como HTTP.
- Por lo tanto, el script de Python (o un paso previo en n8n) convierte las imágenes de cada página de la factura a su representación en Base64.
4. Extracción de datos con Gemini 1.5 Pro:
- La representación en Base64 de las imágenes de la factura, junto con un prompt cuidadosamente diseñado, se envía a la API de Gemini 1.5 Pro a través de una llamada HTTP Request.
- La precisión y eficacia de esta etapa dependen fundamentalmente del prompt de ingeniería utilizado. No se trata solo de pedirle al modelo que extraiga campos, sino de instruirle sobre cómo entender la estructura del documento, manejar casos complejos (como facturas de varias páginas), identificar el tipo de servicio, normalizar datos y validar la información.
5. El prompt
El prompt proporcionado es un ejemplo excelente de cómo guiar a un modelo multimodal para una tarea estructurada de extracción. Los conceptos más importantes que aborda y que son esenciales para su éxito son:
- Gestión de documentos múltiples/multi-página: Instruye explícitamente al modelo sobre cómo identificar facturas individuales dentro de un documento que pueda contener varias y, crucialmente, cómo agrupar correctamente las páginas que pertenecen a una única factura. Esto se basa en criterios lógicos como el número de cuenta y la fecha.
- Normalización de datos: Especifica la necesidad de estandarizar ciertos campos, como el número de cuenta (eliminando espacios), antes de usarlos para comparaciones o agrupaciones.
- Criterios de identificación de nueva factura: Define reglas claras y lógicas (cambio de número de cuenta, fecha o proveedor) para determinar cuándo comienza una nueva factura dentro de un flujo de páginas. Esto evita errores de segmentación.
- Clasificación basada en claves contextuales: Indica al modelo que identifique el tipo de servicio (agua, luz, gas) buscando pistas específicas dentro del documento (unidades de consumo, encabezados de sección, logos).
- Identificación precisa del proveedor: Aclara que el proveedor es quien emite la factura, no el cliente, y sugiere dónde buscar esta información (logos, secciones de pago).
- Extracción estructurada de direcciones: Guía la extracción de la dirección de servicio en componentes separados (línea, ciudad, código postal, etc.), incluyendo información adicional como números de apartamento o unidad.
- Manejo de formatos especiales: Advierte sobre la necesidad de tratar cuidadosamente valores negativos o formatos específicos para montos.
- Exclusión de criterios de división irrelevantes: Prohíbe explícitamente dividir una factura basándose en la presencia de múltiples medidores o direcciones de servicio bajo la misma cuenta, asegurando que toda la información de una cuenta se mantenga unida.
- Formato de salida estricto: Requiere que la salida sea un array JSON válido con un objeto por cada factura extraída, facilitando su posterior procesamiento automatizado.
6. Orquestación y procesamiento avanzado con n8n y agentes de IA:
El output JSON estructurado de Gemini 1.5 Pro es recibido por un flujo de trabajo en n8n.
- Aquí entra en juego lo que consideramos la parte más sofisticada y mejor estructurada de la solución: la utilización de un Agente de IA (Agent Tool) potenciado por un modelo avanzado, como GPT-4.1 (OpenAI), integrado en n8n. Este agente actúa como el cerebro operativo que guía el resto del proceso.
La importancia de la validación de datos
La validación es una capa esencial de protección de la integridad. Incluso con modelos de extracción muy precisos, siempre existe un pequeño margen de error o la posibilidad de encontrar formatos inesperados. Validar los datos antes de la inserción en la base de datos asegura que:
- Se cumplen las restricciones de la base de datos (tipos de datos, campos obligatorios).
- Los datos son lógicamente consistentes y fiables para reportes, análisis y operaciones posteriores.
- Se evitan errores que podrían corromper la base de datos o requerir corrección manual posterior.
Conclusiones y beneficios del proyecto
Este proyecto demuestra el poder transformador de la combinación de tecnologías de OCR avanzadas, modelos de lenguaje potentes (LLMs) y herramientas de automatización de flujos de trabajo. Al implementar esta solución, la empresa constructora logra:
- Aumento drástico de la eficiencia: El procesamiento de miles de facturas que antes tomaba días o semanas de trabajo manual se realiza ahora de forma automatizada en cuestión de minutos u horas.
- Reducción significativa de costes: Se liberan recursos humanos de tareas repetitivas para enfocarse en actividades de mayor valor añadido.
- Mejora de la precisión: Se minimiza el error humano gracias a la extracción y validación automatizada, lo que resulta en datos más fiables para la gestión financiera.
- Creación de un archivo digital estructurado: OneDrive sirve como un repositorio centralizado y accesible de todas las facturas.
- Escalabilidad: La solución está diseñada para manejar un volumen creciente de facturas sin un incremento lineal en los recursos necesarios.
La clave del éxito reside no solo en la elección de modelos de IA de vanguardia (Gemini 1.5 Pro para OCR preciso de documentos complejos, GPT-4.1 como agente inteligente), sino también en la ingeniería de prompts meticulosa y la arquitectura robusta del flujo de trabajo en n8n. La implementación estratégica de técnicas como la Chain of Thought («THINK») en el agente de IA añade una capa crucial de fiabilidad y razonamiento estratégico, permitiendo al sistema manejar situaciones complejas, interactuar dinámicamente con sistemas externos (la base de datos vía API) y validar información crítica antes de proceder.
En resumen, hemos transformado un proceso manual ineficiente y propenso a errores en un flujo de trabajo digital inteligente y escalable, demostrando cómo la IA puede resolver desafíos operativos concretos y generar valor tangible para las empresas.

¿Qué es lo siguiente?
Si tienes una idea similar que quieras implantar en tu empresa, no dudes en contactarme. Puedes escribirme a pablo@ideasforge.io.
Volver a la página principal